




























As Avinash Kaushik says, “All data in aggregate is crap.” Segmentation and data-driven personalization are some of the most powerful tools marketers and product managers have at their disposal.
Instead of treating every visitor or user the same way, you can deliver experiences based on the unique behavioral, psychographic, demographic, and firmographic characteristics of your users.
At this point, I think everyone is bought into the idea of segmentation, as well as its logical extension- personalization.
In fact, according to an Evergage study, “92% of marketers reported using personalization techniques in their marketing, yet 55% of marketers don’t feel they have sufficient customer data to implement effective personalization.”
The theory behind segmentation and personalization is often rosier than the reality of its execution. In reality, you need three core components to make a personalization program work.
This article will walk through those core essentials, and then I’ll explain the difference between traditional segmentation and predictive segmentation (driven by machine learning).
- What is Predictive Segmentation?
- Data, Content, and Targeting Rules: The Basics of Personalization
- Predictive Segmentation vs. Business Logic
- Business Logic Segmentation
- Predictive Segmentation
- How to Get Started with Data-Driven Personalization
By the end of this article, you’ll have a good idea of how to implement data-driven personalization and predictive segmentation.
First, What is ‘Predictive Segmentation’?
Segmentation, at a high level, is the process of dividing something into separate parts or sections.
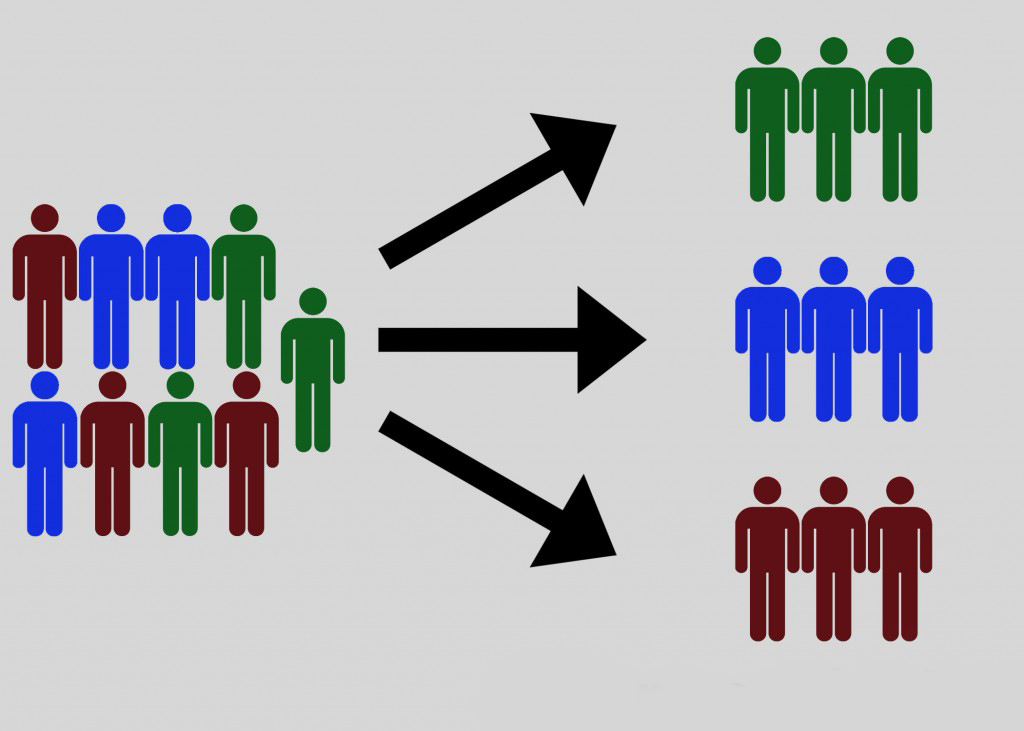
When we say “segmentation,” we typically mean “market segmentation” or “customer segmentation,” or perhaps “behavioral segmentation.” This type of segmentation is the process of identifying and defining characteristics that delineate one sub-group or section of customers from the other.
This is usually done via business logic. For instance, we could say that mobile device users are a separate segment from desktop users. Or more commonly, we can group visitors by geographic representation: NAM vs EMEA users.
Predictive segmentation is when you identify user clusters programmatically or by using machine learning. Read more - via @webengage Share on XIn this method, you typically have a goal or outcome that you’re tracking, and you can work backward to identify common characteristics that sub-groups share in relation to this goal.
For example, you may track “email list signup conversions” on your blog. Predictive segmentation may discover that there are distinct groups that behave consistently when visiting your blog.
One group of mobile visitors tends to spend very little time on site and bounces at a high rate. Another group of desktop visitors from organic channels spends very little time and bounces at a similarly high rate.
You could discover these segments on your own using data analysis, but predictive segmentation tools seek to identify and cluster these user segments. Usually, tools like this try to predict the actions these segments will take so you can trigger personalization rules.
Data, Content, and Targeting Rules: The Basics of Personalization
To successfully deliver personalized experiences to different user segments, you need three components:
- Data
- Content
- Targeting Logic
1. Data
Data underpins everything when it comes to segmentation and personalization.
If you don’t have the data you need when you need it, you can’t identify user segments let alone trigger personalized experiences for them. Additionally, if your data is imprecise and/or incomplete, your personalization may be ineffective.
Therefore, before you ever do any segmentation, confirm these three things:
-
- Are you measuring everything you need to? Do you have goals set up properly, custom dimensions, etc.? Is your data “complete”?
- Is your data trustworthy? It need not be 100% ‘accurate’, but is it consistent and precise in its logging?
- Is your data accessible when you need it? How much cleaning and preparation do you need to do to derive insights from your data? Is it aggregated and connected to other sources (social, web, email, customer data)? Is it stored in a place that can be used and analyzed immediately?
Further, you’ll want to connect your data sources to some centralized storage table. Nowadays, customer data platforms (CDPs) such as Hull.io and Segment are the name of the game, but you can also use CRMs like HubSpot to centralize, store, and operationalize your marketing and customer data.
These become important as you connect your pre-purchase data to your post-purchase data. This allows you to identify segments based on important business metrics such as their predicted lifetime value or churn rate.
2. Content
The content portion is much easier to grok.
Essentially, if you want to do personalization, you first define a user segment using your data sources. Then you also need to create a new experience to deliver to that segment.
Creating new content or experiences requires resources, both in terms of time and money. Further, the more content and experiences you’re delivering and managing, the more complexity you build up in your organization.
Matt Gershoff, CEO of Conductrics, gave a great analogy in the Digital Analytics Power Hour podcast about this.
He described personalization as essentially creating a multiverse.
Running one version of your website to everyone is like having one universe, and perhaps an A/B test allows you to run a counterfactual to see what life would look like in a parallel universe (or “version B”).
In an A/B test, you want to see if version B is a better “universe” for your visitors as defined by your goal conversion, and if you find that it is indeed optimal, you close universe A (the original) and again re-enter a singular universe.
However, multiple content variants delivered to multiple unique segments is like keeping open several distinct universes wherein the experiences are unique to those segments.
The magic of this is that you can increase the value of your website by increasing the value of each individual segment and their experience, but you can understand how opening up thousands of “universes” would be costly both in terms of creating and managing all those experiences.
3. Targeting Logic
Finally, if you’ve got useful data and resources to create content, you need to determine how exactly you trigger targeting or personalization logic to user segments.
This is how you connect the data with the experiences.
You can use business logic (assuming certain segments should have certain values – you can even A/B test them), or you can introduce machine learning and predictive segmentation/RFM to classify your users into different groups – most valuable users, about to churn users, dormant users, etc. Using RFM segmentation, you can also learn which user segments respond more variably to which content experiences.
Technically, for this step, you need a content delivery system that is either connected to your database or can integrate and pull from your database. WebEngage is a full-stack marketing automation and retention operating system that can connect seamlessly with your CRM and help you engage your users on a 1:1 basis across channels like Email, SMS, WhatsApp, Facebook, Mobile & Web Push, and more.
Again, though, the more targeting rules you trigger, the more complex the system you build. So there’s a tradeoff in the ROI you can exploit by targeting a given segment and the marginal complexity introduced to the system. It’s easy to merge first names to custom email tokens (most email tools do that out of the box now), but that doesn’t tell you the ROI of that targeting rule.
That’s why, instead of just setting up tons of personalization just because you can, you should look at it strategically and methodologically, determining the ROI and efficiency of targeting a given segment.
Predictive Segmentation vs. Business Logic
I’ve already dropped some jargon with regards to targeting logic — such as “business logic” and “predictive segmentation.”
Business logic essentially stands on the other side of the spectrum from “data-driven personalization,” “predictive segmentation,” or “machine learning-based personalization.” But both of these methods have the same aim: identify segments to be treated with personalized experiences.
Let’s define these two poles and how they differ.
Business Logic Segmentation
“Business logic” is the usual method by which people choose targeting rules. In this method, you basically decide which segments have the highest impact opportunities using historical data and correlations or business logic, strategy, or opinions. There are three main ways you can derive business logic targeting rules:
- Opinion-driven personalization
- Post-test segmentation
- Exploratory data analysis
1. Opinion-driven personalization
For example, you may simply want to avoid triggering an invasive popup on mobile for purely subjective reasons. It’s not a good user experience, so you avoid it. You don’t even need data to predict that segment’s reaction.
This is the method that the vast majority of companies are using when they say they are doing segmentation or data-driven personalization. They arbitrarily guess which segment will respond favorably to which experience and personalize it based on their opinion.
2. Post-test segmentation
Less common (but more effective), however, is running an experiment and then doing post-test analysis to figure out if certain variations had higher impact areas on certain segments.
Imagine you’re running a test on an eCommerce checkout flow.
You decide to test multiple variants – one variant with a series of trust and security symbols, one with a popup that uses urgency messages, and one with no symbols (the original version).
After analyzing the experiment, you’ve determined that version B “won” and that it has an estimated uplift of 10%. A great win.
However, you dig into the data and look at high-impact segments, such as mobile vs desktop visitors, returning vs new visitors, and visitors from the US vs non-US visitors.
In doing so, you’ve discovered that iPhone users actually converted 35% better on variant B. iPhone users represent a substantial percentage of your audience, roughly 25% of all visitors. This means that triggering a personalized experience to this segment could be worthwhile and ROI positive.
Furthermore, Android users actually converted 20% lower on variant B and 15% higher than control on variant C. Android users represent 10% of your audience, so again, a pretty large population.
So you could just launch variant B because it won in aggregate. Or alternatively, you could set up targeting rules to trigger iPhone users to receive variant B and Android users to receive variant C. Everyone else gets the original.
3. Exploratory data analysis and correlations
The final way you can use “business logic” for segmentation is by simply exploring the data you’ve got access to and looking for correlations between segment characteristics and the probability of conversion.
You may find, for instance, that iPhone users convert higher. Or people who watch a video on your homepage. Or male Android users from Kansas who filled out half of your form fields and returned 3 times in one week.
Here’s the problem with this approach: look at enough segments and you’ll find a correlation. That’s a signal vs noise issue.
The bigger issue with this approach is that correlation doesn’t imply causation.
Just because a desktop return visitor from California converts higher doesn’t mean that’s a segment worth targeting via data-driven personalization.
Your best bet in the business logic world is to run experiments and discover high-value segments via post-test segmentation. Then you calculate the ROI of a given targeting rule and run a follow-up experiment only targeting that segment.
You can then tease out causality and the true ROI of maintaining that targeting rule. For more information on this approach, read Andrew Anderson’s wonderful walkthrough on the topic.
Predictive Segmentation
Predictive segmentation (or by another name, “data-driven” or “AI-based” segmentation) seeks to remove human intuition and manual data analysis from the definition of segments and setting up targeting rules.
There are several ways you can define segments using machine learning. It just depends on what your goals are and what you’re hoping to accomplish with these segments. Here we’ll cover three keys methods:
- Clustering
- Classification
- Experimentation + predictive pooling
1. Clustering
First up, if you simply want to identify and understand different user personas or segments, clustering algorithms (or unsupervised machine learning) is a technique used to group together segments based on common characteristics.
This is something I worked on at CXL Institute a few years ago.
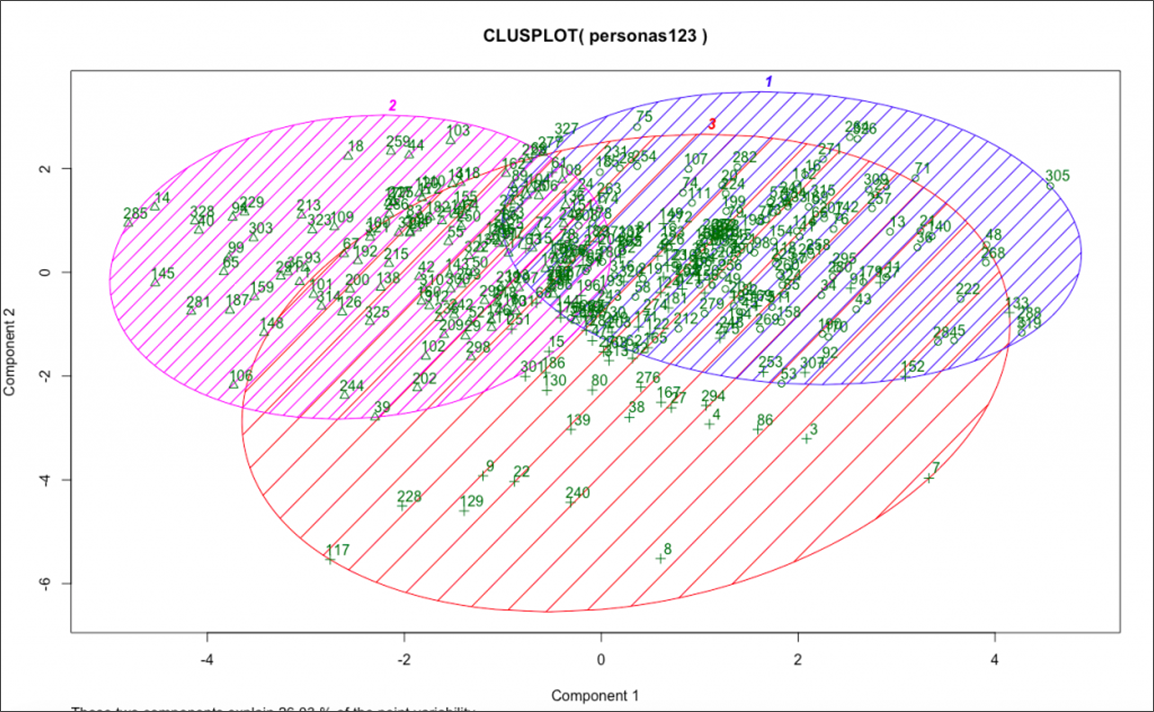
We sent out surveys to our customer base with a mixture of scale responses, categorical variables, and open-ended questions. I then codified their responses and ran the K Means clustering algorithm on them.
This identified roughly three distinct segments based on their responses. I then layered on the qualitative insights from each of these segments and interviewed individuals highly representative of each segment. This allowed us to deeply understand our existing customer base and their differing desires, challenges, and behaviors.
If you want to do clustering, know that it’s mostly exploratory and for knowledge building. It won’t tell you the ROI of sending personalized marketing communication to one of these segments, nor will it tell you which segments are likely to respond to which experiences. For example, you may find that a certain segment of email subscribers open more emails and have higher lifetime value, but you still need to do the creative work of ideating new content and experiences to test.
But it’s a good base layer to start with data-driven personalization.
You’ll also need a decent analyst that can code R or Python or at least a tool like Squark that allows for no code predictive analytics.
2. Classification
Machine learning tends to be delineated between supervised and unsupervised learning. Where clustering algorithms are unsupervised, classification algorithms are supervised.
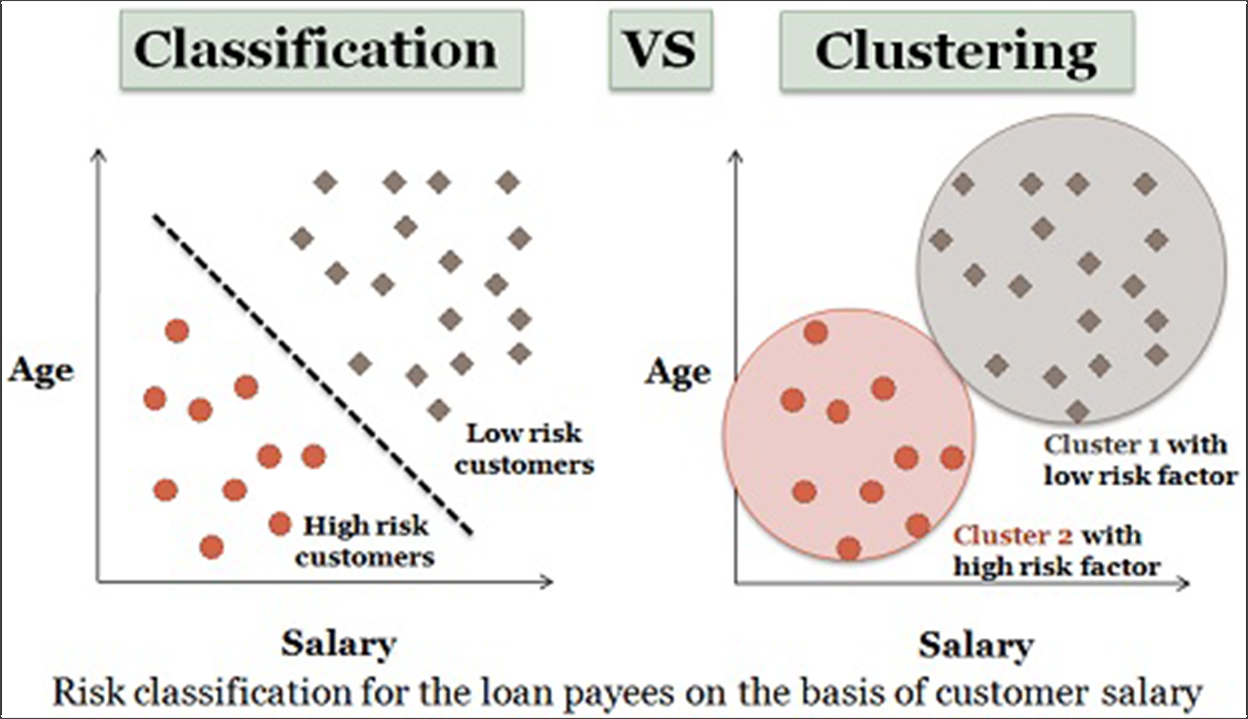
This means that you’ve got a dataset that includes various “features” (in our case, this could be things like device type, pages visited, company size, or any characteristic we can collect about visitors) and then you have outcomes that you want to predict (in our case, conversions or revenue or LTV).
There are a massive amount of methodologies and algorithms that try to predict outcomes based on data features, some of which include linear regressions, logistic regressions, random forests, and neural networks.
If you want to use this method, you’ll want a great analyst who can fit a model to your data properly (otherwise the predictions are useless), or buy a tool like Squark or DataRobot. These tools enable analysts and business folks to fit different models to their data and predict outcomes without coding the algorithms themselves.
3. Experimentation + Predictive Segmentation
Often the best way to go about finding lucrative user segments is by going about your normal course of controlled experimentation and using a tool (or analysis method) that detects promising segments.
Conductrics, for example, shows you a highly interpretable decision tree that calculates probabilities of conversion success for individual segments that correspond to each variant you tested.
Bonus points if your predictive targeting tool has data visualization that shows you, in simple illustrations, what targeting rules you’ve set up and the estimated ROI and success probability of these rules.
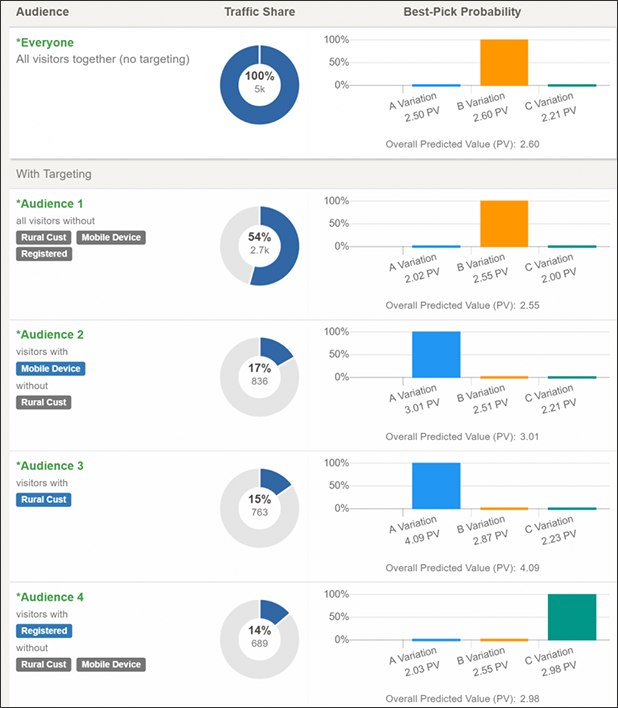
This is cool because you not only get the probability of success, but you can choose whether or not to target that segment based on the value of it.
Male android return visitors from rural Kentucky? Maybe not worth setting up a new targeting rule. But maybe it’s worth targeting Californians if they are a large population and respond very favorably to a given experience.
How to Get Started with Data-Driven Personalization
While it may be tempting to dive into the deep end of data-driven personalization, I recommend starting slowly.
It’s unknown what the true value of any given personalization rule is, and often the marginal returns of increased personalization fall short of the marginal complexity cost introduced.
Therefore, I’ll introduce three personalization approaches of escalating complexity (and let’s assume the ‘crawl’ stage is just getting your data in order and the resources/tools required to deliver personalized experiences).
Stage One: Walk
Therefore, before you invest in a predictive targeting tool, you may want to use Andrew Anderson’s methodology, which can be a simple continuation of your normal experimentation program (side note: don’t have traffic for experiments? Personalization is not for you. The marginal returns will not be worth it at that traffic level. Hit big swings instead).
Here’s the gist of the methodology:
- Create multiple executions of the message or experience
- Serve all the offers to everyone via a controlled experiment
- Look at the results by segment and calculate the total gain by giving a differentiated experience. Make sure you correct for multiple comparisons when analyzing many segments.
- Push live the highest revenue-producing opportunity found (or run a follow-up experiment on only that segment with the experiences you tested on the full audience).
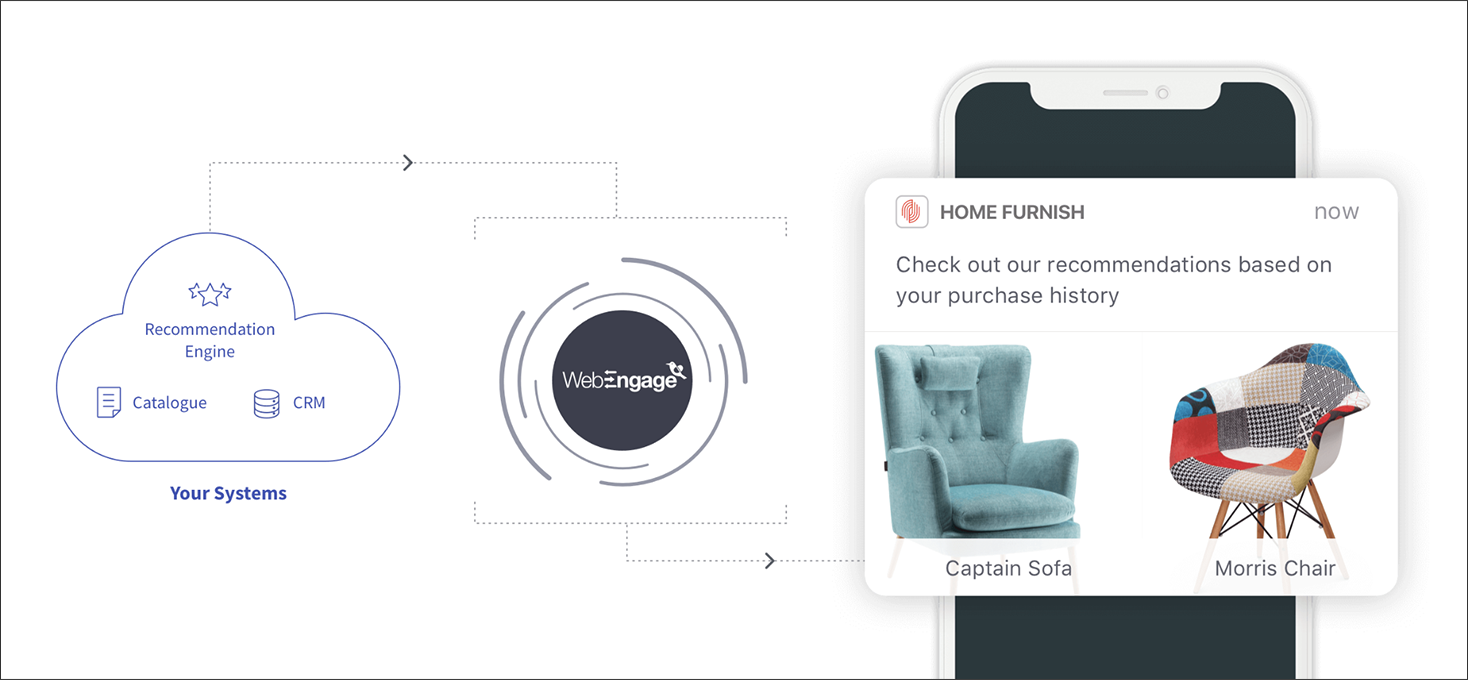
You can use dedicated A/B testing platforms or you can use an integrated marketing automation platform. The latter will help you personalize messages on multiple channels, not just the web or app, and you can offer personalized product recommendations, increase your revenue and CLTV, improve content/product discovery, and much more.
Stage Two: Run
After getting some wins here, you may want to invest in a no-code predictive analytics solution like Squark (or if you can code the algorithms in-house, by all means). The basic process looks something like this:
Determine your success metrics
Collect and clean your data, splitting your data set into training and test data.
Make sure you have a myriad of dimensions or features in your data that can be used to predict the outcome.
Determine which features are predictive of your success metrics.
Calculate the ROI of personalizing experiences for those segments. Again, if it’s too small of a population, it may not be worth it.
Now the important part: once you’ve defined a feature or dimension that is predictive of success (say it’s return visitors), you’ve still not figured out which experiences are more likely to work on that segment.
The hard work still remains: that is, creating new great experiences and running experiments to determine the effectiveness and ROI of your new experiences.
You’ll still want to invest in a content delivery solution here like WebEngage in order to target specific segments.
Stage Three: Fly
Finally, if you want to incorporate predictive targeting into your normal experimentation and optimization workflow, you can’t beat a tool like Conductrics or Dynamic Yield. These tools will help you identify segments and deliver personalized experiences while giving you interpretable decision rules and ROI attribution reports.
Conclusion
In a world dominated by headlines and conference talks about artificial intelligence being a silver bullet, you might be surprised to learn that the “data-driven personalization” or “predictive segmentation” process doesn’t do all of the work for you.
It can help you leverage your data and save a lot of time (and mistakes). You can more easily and accurately identify lucrative segments, so long as you have the proper data in place and it’s accessible when you need it.
It can’t, however, make the decision for you as to whether or not to leverage that segment. You’ll still have to weigh the pros and cons, the costs, and the benefits.
Luckily, however, the process of identifying and grouping segments has never been easier, nor has it ever been easier to deliver and manage multiple different experiences. A marketing automation tool can be plugged into your data source or CRM. You can manage and deliver unlimited personalized experiences via any channel you want – paid ads, social, web, push, email, etc.
It’s a great time to be a data-driven marketer.
Take a demo with WebEngage and Leverage The Power Of Automation For Your Business


 Tina Verma
Tina Verma
 Ananya Nigam
Ananya Nigam
 Ajit Singh
Ajit Singh

 Harshita Lal
Harshita Lal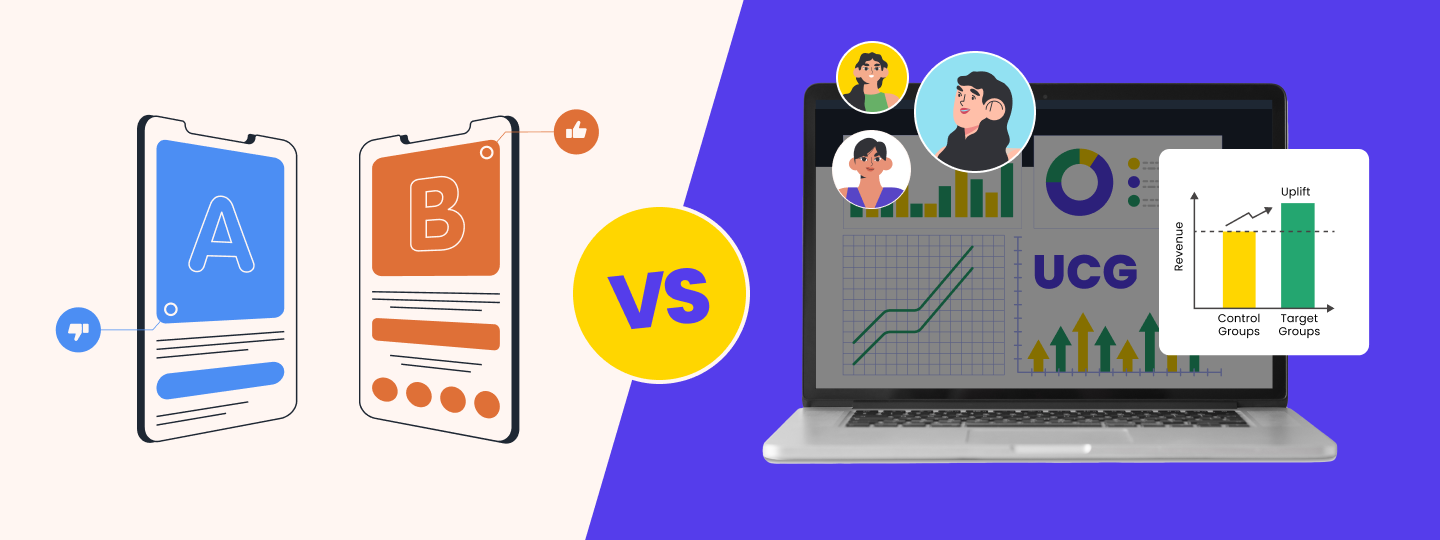
 Priyam Jha
Priyam Jha